Research
2025
- Convolutional Autoencoder With Sequential and Channel Attention for Robust ECG Signal Denoising With Edge Device ImplementationAlif Wicaksana Ramadhan, Syifa Kushirayati, Salsabila Aurellia, and 7 more authorsIEEE Access, Mar 2025
Electrocardiograms (ECG) are vital for diagnosing various cardiac conditions but are often corrupted by noise from multiple sources, which can hinder accurate interpretation. Denoising ECG signals is particularly challenging because noise usually overlaps with the frequency range of the signal of interest. We proposed a convolutional autoencoder with sequential and channel attention (CAE-SCA) to address this issue. Sequential attention (SA) is based on long short-term memory (LSTM), which captures causal-temporal relationships. Meanwhile, channel attention (CA) is used to emphasize important features within channels. SA is applied to the skip connection of each encoder block, and CA is applied after each decoder block. We validated the CAE-SCA using the MIT-BIH and SHDB-AF databases as clean ECG signals, with the MIT-BIH Noise Stress Test Database as the noise source. Experimental results give an average SNR value of 16.187 dB, RMSE of 0.059, and PRD value of 18.529 in the MIT-BIH database. While in the SHDB-AF dataset, the model obtained 15.308 dB of SNR, 0.049 of RMSE, and 19.220 of PRD. These results demonstrate our CAE-SCA outperforms all the state-of-the-art methods across all tested metrics. For efficiency, CAE-SCA achieved competitive results in the metrics of floating-point operations (FLOPs), inference time, and total parameters. This allowed CAE-SCA to be implemented in edge devices as we tested using our custom ECG acquisition circuit. A significance test further confirms a statistically significant improvement in SNR values achieved by the CAE-SCA compared to baseline models, suggesting the CAE-SCA’s potential for advancing ECG processing in healthcare applications.
@article{10925413, author = {Wicaksana Ramadhan, Alif and Kushirayati, Syifa and Aurellia, Salsabila and Luthfi Ramadhan, Mgs M. and Hannan Hunafa, Muhammad and Febrian Rachmadi, Muhammad and Jasa Mantau, Aprinaldi and Nurmaini, Siti and Mandala, Satria and Jatmiko, Wisnu}, journal = {IEEE Access}, dimensions = {true}, title = {Convolutional Autoencoder With Sequential and Channel Attention for Robust ECG Signal Denoising With Edge Device Implementation}, year = {2025}, month = mar, volume = {13}, number = {}, pages = {54407-54422}, keywords = {Electrocardiography;Autoencoders;Noise reduction;Heart;Decoding;Convolution;Databases;Convolutional neural networks;Long short term memory;Monitoring;Autoencoder;convolutional neural networks (CNN);ECG;signal denoising;LSTM}, doi = {10.1109/ACCESS.2025.3550949} }

2024
- Time-Distributed Vision Transformer Stacked With Transformer for Heart Failure Detection Based on Echocardiography VideoMgs M. Luthfi Ramadhan, Adyatma W. A. Nugraha Yudha, Muhammad Febrian Rachmadi, and 3 more authorsIEEE Access, Dec 2024
Heart failure is a disease many consider to be the number one global cause of death. Despite its mortality, heart failure is still underdiagnosed clinically, especially in a remote area that experiences cardiologists shortage. Existing studies have employed artificial intelligence to help with heart failure screening and diagnosis processes based on echocardiography videos. Specifically, most existing studies use a convolutional neural network that only captures the local context of an image hindering it from learning the global context of an image. Moreover, the frame sampling algorithms only sample certain consecutive frames which makes it questionable whether the dynamic of the left ventricle during a cardiac cycle is included. This study proposed a novel deep learning model consisting of a time-distributed vision transformer stacked with a transformer. The time-distributed vision transformer learns the spatial feature and then feeds the result to the transformer to learn the temporal feature and make the final prediction afterward. We also proposed a frame sampling algorithm by squeezing the video and sampling the frame after a certain interval. Consequently, the video still contains the sequential information up until the end of the video with some in-between frames removed by a certain interval. Thus, the dynamic of the left ventricle is preserved. Our proposed method achieved an F1 score of 95.81%, 96.19%, and 93.43% for the apical four chamber view, apical two chamber view, and parasternal long axis view respectively. The overall trustworthiness of our model is quantified using the NetTrustScore and achieved a score of 0.9712, 0.9767, and 0.9527 for the apical four chamber view, apical two chamber view, and parasternal long axis view respectively.
@article{10776969, author = {Ramadhan, Mgs M. Luthfi and Yudha, Adyatma W. A. Nugraha and Rachmadi, Muhammad Febrian and Tandayu, Kevin Moses Hanky Jr and Liastuti, Lies Dina and Jatmiko, Wisnu}, journal = {IEEE Access}, title = {Time-Distributed Vision Transformer Stacked With Transformer for Heart Failure Detection Based on Echocardiography Video}, year = {2024}, month = dec, volume = {12}, number = {}, dimensions = {true}, pages = {182438-182454}, keywords = {Echocardiography;Transformers;Convolutional neural networks;Feature extraction;Hafnium;Computer vision;Heart;Cardiovascular diseases;Data analysis;Wrapping;Deep learning;pattern recognition;heart failure;echocardiography;computer vision}, doi = {10.1109/ACCESS.2024.3510774}, publisher = {IEEE}, } - Building Damage Assessment Using Feature Concatenated Siamese Neural NetworkMgs M. Luthfi Ramadhan, Grafika Jati, and Wisnu JatmikoIEEE Access, Jan 2024
Fast and accurate post-earthquake building damage assessment is an important task to do to define search and rescue procedures. Many approaches have been proposed to automate this process by using artificial intelligence, some of which use handcrafted features that are considered inefficient. This research proposed end-to-end building damage assessment based on a Siamese neural network. We modify the network by adding a feature concatenation mechanism to enrich the data feature. This concatenation mechanism creates different features based on each output from the convolution block. It concatenates them into a high-dimensional vector so that the feature representation is more likely to be linearly separable, resulting in better discrimination capability than the standard siamese. Our model was evaluated through three experimental scenarios where we performed classification of G1 or G5, G1-G4 or G5, and all the five grades of EMS-98 building damage description. Our models are superior to the standard Siamese neural network and state-of-the-art in this field. Our model obtains f1-scores of 79.47%, 54.09%, 40.64% and accuracy scores of 87.24%, 95.28%, and 42.57% for the first, second, and third experiments, respectively.
@article{10418211, author = {Ramadhan, Mgs M. Luthfi and Jati, Grafika and Jatmiko, Wisnu}, journal = {IEEE Access}, dimensions = {true}, title = {Building Damage Assessment Using Feature Concatenated Siamese Neural Network}, year = {2024}, month = jan, volume = {12}, number = {}, pages = {19100-19116}, keywords = {Neurons;Feature extraction;Earthquakes;Point cloud compression;Laser radar;Classification algorithms;Disaster management;Neural networks;Classification;deep learning;disaster;earthquake;LiDAR;siamese neural network}, doi = {10.1109/ACCESS.2024.3361287}, publisher = {IEEE}, } - JIKI
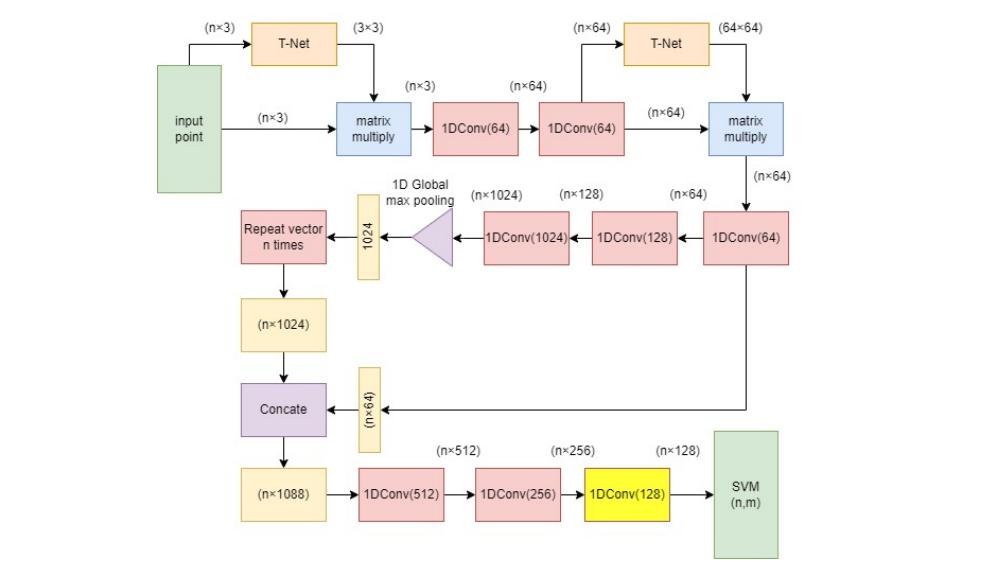 An alternative for kernel SVM when stacked with a neural networkMgs M Luthfi RamadhanJurnal Ilmu Komputer dan Informasi, Feb 2024
An alternative for kernel SVM when stacked with a neural networkMgs M Luthfi RamadhanJurnal Ilmu Komputer dan Informasi, Feb 2024Many studies stack SVM and neural network by utilzing SVM as an output layer of the neural network. However, those studies use kernel before the SVM which is unnecessary. In this study, we proposed an alternative to kernel SVM and proved why kernel is unnecessary when the SVM is stacked on top of neural network. The experiments is done on Dublin City LiDAR data. In this study, we stack PointNet and SVM but instead of using kernel, we simply utilize the last hidden layer of the PointNet. As an alternative to the SVM kernel, this study performs dimension expansion by increasing the number of neurons in the last hidden layer. We proved that expanding the dimension by increasing the number of neurons in the last hidden layer can increase the F-Measure score and it performs better than RBF kernel both in term of F-Measure score and computation time.
@article{ramadhan2024alternative, title = {An alternative for kernel SVM when stacked with a neural network}, dimensions = {true}, author = {Ramadhan, Mgs M Luthfi}, journal = {Jurnal Ilmu Komputer dan Informasi}, volume = {17}, number = {1}, pages = {1--7}, month = feb, doi = {10.21609/jiki.v17i1.1172}, year = {2024} } - JIKI
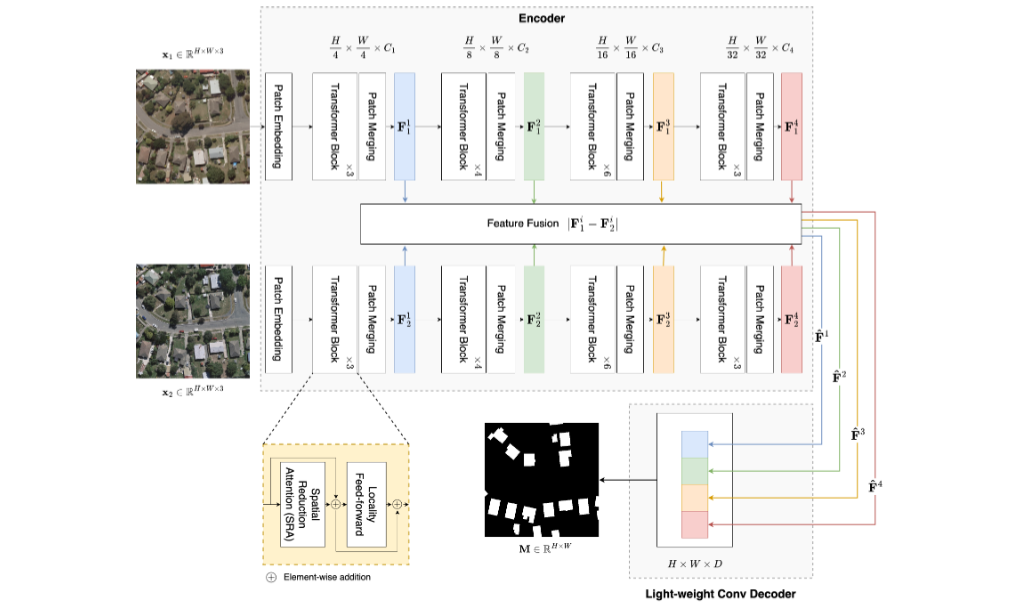 Improving Remote Sensing Change Detection Via Locality Induction on Feed-forward Vision TransformerLhuqita Fazry, Mgs M Luthfi Ramadhan, and Wisnu JatmikoJurnal Ilmu Komputer dan Informasi, Feb 2024
Improving Remote Sensing Change Detection Via Locality Induction on Feed-forward Vision TransformerLhuqita Fazry, Mgs M Luthfi Ramadhan, and Wisnu JatmikoJurnal Ilmu Komputer dan Informasi, Feb 2024The main objective of Change Detection (CD) is to gather change information from bi-temporal remote sensing images. The recent development of the CD method makes use of the recently proposed Vision Transformer (ViT) backbone. Despite ViT being superior to Convolutional Neural Networks (CNN) at modeling long-range dependencies, ViT lacks a locality mechanism, a critical property of pixels that comprise natural images, including remote sensing images. This issue leads to segmentation artifacts such as imperfect changed region boundaries on the predicted change map. To address this problem, we propose LocalCD, a novel CD method that imposes the locality mechanism into the Transformer encoder. Particularly, it replaces the Transformer’s feed-forward network using an efficient depth-wise convolution between two 1 \times 1 convolutions. LocalCD outperforms ChangeFormer by a significant margin. Specifically, it achieves an F1-score of 0.9548 and 0.9243 on CDD and LEVIR-CD datasets.
@article{Fazry_Mgs_M_Luthfi_Ramadhan_Jatmiko_2024, title = {Improving Remote Sensing Change Detection Via Locality Induction on Feed-forward Vision Transformer}, volume = {17}, url = {https://jiki.cs.ui.ac.id/index.php/jiki/article/view/1188}, doi = {10.21609/jiki.v17i1.1188}, number = {1}, journal = {Jurnal Ilmu Komputer dan Informasi}, author = {Fazry, Lhuqita and Ramadhan, Mgs M Luthfi and Jatmiko, Wisnu}, year = {2024}, month = feb, dimensions = {true}, pages = {37-48} }




2023
- Change Detection of High-Resolution Remote Sensing Images Through Adaptive Focal Modulation on Hierarchical Feature MapsLhuqita Fazry, Mgs M. Luthfi Ramadhan, and Wisnu JatmikoIEEE Access, Jul 2023
One of the major challenges in the change detection (CD) of high-resolution remote sensing images is the high requirement for computational resources. Besides, to get the best change detection result, it must spot only the important changes while omitting unimportant ones, which requires learning complex interactions between multi-scale objects on the images. Despite Convolution Neural Network (CNN) efficiently extracting features from such images, it has a limited receptive field resulting in sub-optimal representation. On the other hand, Vision Transformer (ViT) can capture long-range dependencies. Still, it suffers from quadratic complexity concerning the number of image patches, especially for high-resolution images. Furthermore, both approach can not model the interactions among multi-scale image patches, which is essential for a model to fully understand the natural images. We propose FocalCD, a CD method based on a recently proposed focal modulation architecture capable of learning short and long dependencies to solve this problem. It is attention-free and does not suffer from quadratic complexity. Also, it supports learning multi-scale interaction by adaptively selecting the discriminator regions from multi-scale levels. Besides the efficient yet powerful encoder, FocalCD has an effective multi-scale feature fusion and pyramidal decoder network. FocalCD achieves strong empirical results on various CD datasets, including CDD, LEVIR-CD, and WHU-CD. It reaches F1 scores of 0.9851, 0.952, and 0.9616 on datasets CDD, LEVIR-CD, and WHU-CD outperforming state-of-the-art CD methods while having comparable or even lower computation complexity.
@article{10173482, author = {Fazry, Lhuqita and Ramadhan, Mgs M. Luthfi and Jatmiko, Wisnu}, journal = {IEEE Access}, dimensions = {true}, title = {Change Detection of High-Resolution Remote Sensing Images Through Adaptive Focal Modulation on Hierarchical Feature Maps}, year = {2023}, month = jul, volume = {11}, number = {}, pages = {69072-69090}, keywords = {Feature extraction;Transformers;Task analysis;Remote sensing;Convolution;Computer architecture;Decoding;Change detection;FocalCD;focal modulation;multi-scale feature fusion;vision transformer}, doi = {10.1109/ACCESS.2023.3292531}, publisher = {IEEE} } - JIKI
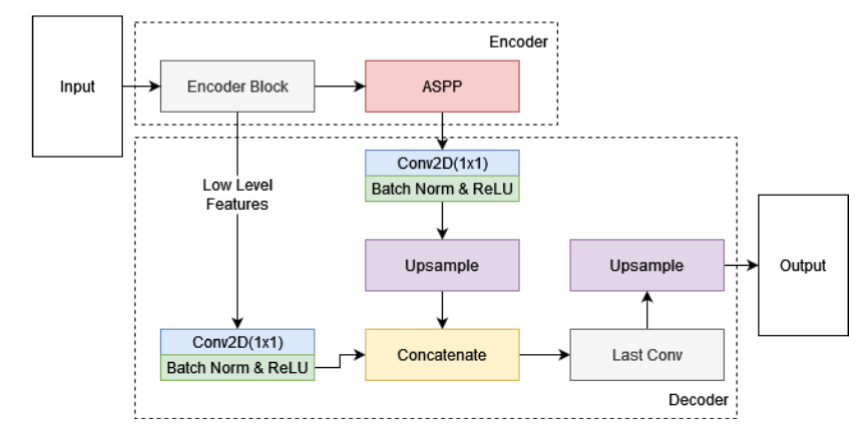 Encoder-Decoder with Atrous Spatial Pyramid Pooling for Left Ventricle Segmentation in EchocardiographyFityan Azizi, Mgs M Luthfi Ramadhan, and Wisnu JatmikoJurnal Ilmu Komputer dan Informasi, Jul 2023
Encoder-Decoder with Atrous Spatial Pyramid Pooling for Left Ventricle Segmentation in EchocardiographyFityan Azizi, Mgs M Luthfi Ramadhan, and Wisnu JatmikoJurnal Ilmu Komputer dan Informasi, Jul 2023Assessment of cardiac function using echocardiography is an essential and widely used method. Assessment by manually labeling the left ventricle area can generally be time-consuming, error-prone, and has interobserver variability. Thus, automatic delineation of the left ventricle area is necessary so that the assessment can be carried out effectively and efficiently. In this study, encoder-decoder based deep learning model for left ventricle segmentation in echocardiography was developed using the effective CNN U-Net encoder and combined with the deeplabv3+ decoder which has efficient performance and is able to produce sharper and more accurate segmentation results. Furthermore, the Atrous Spatial Pyramid Pooling module were added to the encoder to improve feature extraction. Tested on the Echonet-Dynamic dataset, the proposed model gives better results than the U-Net, DeeplabV3+, and DeeplabV3 models by producing a dice similarity coefficient of 92.87%. The experimental results show that combining the U-Net encoder and DeeplabV3+ decoder is able to provide increased performance compared to previous studies.
@article{Azizi_Ramadhan_Jatmiko_2023, title = {Encoder-Decoder with Atrous Spatial Pyramid Pooling for Left Ventricle Segmentation in Echocardiography}, volume = {16}, doi = {10.21609/jiki.v16i2.1165}, number = {2}, journal = {Jurnal Ilmu Komputer dan Informasi}, author = {Azizi, Fityan and Ramadhan, Mgs M Luthfi and Jatmiko, Wisnu}, year = {2023}, month = jul, pages = {163-169}, dimensions = {true}, }


2022
- IWBIS
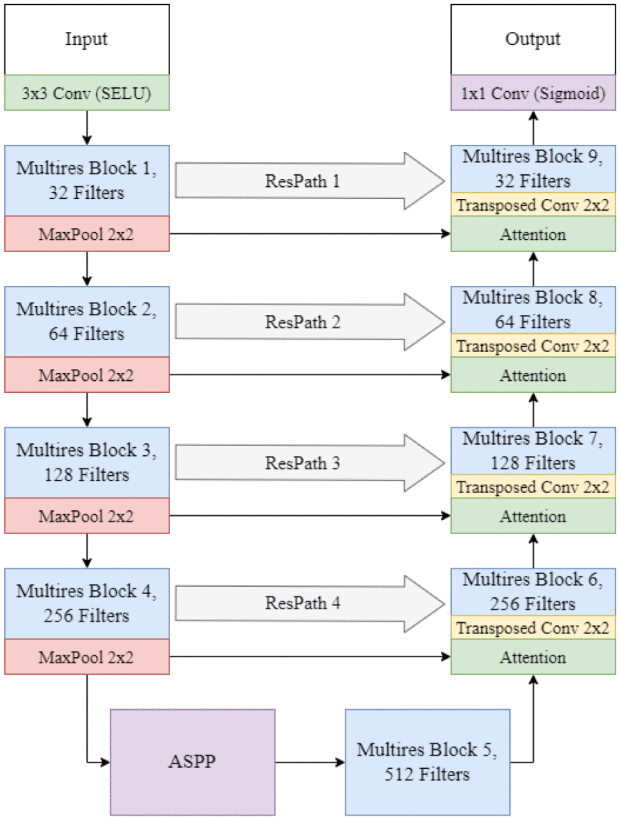 Modified MultiResUNet for Left Ventricle Segmentation from Echocardiographic ImagesFityan Azizi, Akbar Fathur Sani, Rinto Priambodo, and 4 more authorsIn 2022 7th International Workshop on Big Data and Information Security (IWBIS), Oct 2022
Modified MultiResUNet for Left Ventricle Segmentation from Echocardiographic ImagesFityan Azizi, Akbar Fathur Sani, Rinto Priambodo, and 4 more authorsIn 2022 7th International Workshop on Big Data and Information Security (IWBIS), Oct 2022An accurate assessment of heart function is crucial in diagnosing the cardiovascular disease. One way to evaluate or detect the disease can use echocardiography, by detecting systolic and diastolic volumes. However, manual human assessments can be time-consuming and error-prone due to the low resolution of the image. One way to detect heart failure on echocardiogram is by segmenting the left ventricle on the echocardiogram using deep learning. In this study, we modified the MultiResUNet model for left ventricle segmentation in echocardiography images by adding Atrous Spatial Pyramid Pooling block and Attention block. The use of multires blocks from MultiResUnet is able to overcome the problem of multi-resolution segmentation objects, where the segmentation objects have different sizes. This problem has similar characteristics to echocardiographic images, where the systole and diastole segmentation objects have different sizes from each other. Performance measure were evaluated using Echonet-Dynamic dataset. The proposed model achieves dice coefficient of 92%, giving an additional 2% performance result compared to the MultiResUNet.
@inproceedings{9924685, author = {Azizi, Fityan and Sani, Akbar Fathur and Priambodo, Rinto and Karunianto, Wisma Chaerul and Ramadhan, Mgs M Luthfi and Rachmadi, Muhammad Febrian and Jatmiko, Wisnu}, booktitle = {2022 7th International Workshop on Big Data and Information Security (IWBIS)}, dimensions = {true}, title = {Modified MultiResUNet for Left Ventricle Segmentation from Echocardiographic Images}, year = {2022}, month = oct, volume = {}, number = {}, pages = {33-38}, keywords = {Heart;Deep learning;Image segmentation;Echocardiography;Conferences;Information security;Manuals;Heart Function;Echocardiography;Semantic Segmentation;Deep Learning}, doi = {10.1109/IWBIS56557.2022.9924685}, publisher = {IEEE} } - Learning Intelligent for Effective Sonography (LIFES) Model for Rapid Diagnosis of Heart Failure in EchocardiographyLies Dina Liastuti, Bambang Budi Siswanto, Renan Sukmawan, and 10 more authorsJul 2022
Background: The accuracy of an artificial intelligence model based on echocardiography video data in the diagnosis of heart failure (HF) called LIFES (Learning Intelligent for Effective Sonography) was investigated. Methods: A cross-sectional diagnostic test was conducted using consecutive sampling of HF and normal patients’ echocardiography data. The gold-standard comparison was HF diagnosis established by expert cardiologists based on clinical data and echocardiography. After pre-processing, the AI model is built based on Long-Short Term Memory (LSTM) using independent variable estimation and video classification techniques. The model will classify the echocardiography video data into normal and heart failure category. Statistical analysis was carried out to calculate the value of accuracy, area under the curve (AUC), sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), and likelihood ratio (LR). Results: A total of 138 patients with HF admitted to Harapan Kita National Heart Center from January 2020 to October 2021 were selected as research subjects. The first scenario yielded decent diagnostic performance for distinguishing between heart failure and normal patients. In this model, the overall diagnostic accuracy of A2C, A4C, PLAX-view were 92,96%, 90,62% and 88,28%, respectively. The automated ML-derived approach had the best overall performance using the 2AC view, with a misclassification rate of only 7,04%. Conclusion: The LIFES model was feasible, accurate, and quick in distinguishing between heart failure and normal patients through series of echocardiography images.
@article{LIFES, title = {Learning {Intelligent} for {Effective} {Sonography} ({LIFES}) {Model} for {Rapid} {Diagnosis} of {Heart} {Failure} in {Echocardiography}}, volume = {54}, language = {en}, dimensions = {true}, number = {3}, author = {Liastuti, Lies Dina and Siswanto, Bambang Budi and Sukmawan, Renan and Jatmiko, Wisnu and Alwi, Idrus and Wiweko, Budi and Kekalih, Aria and Nursakina, Yosilia and Putri, Rindayu Yusticia Indira and Jati, Grafika and Ramadhan, Mgs M Luthfi and Govardi, Ericko and Nur, Aqsha Azhary}, year = {2022}, month = jul, }


2021
- IWBIS
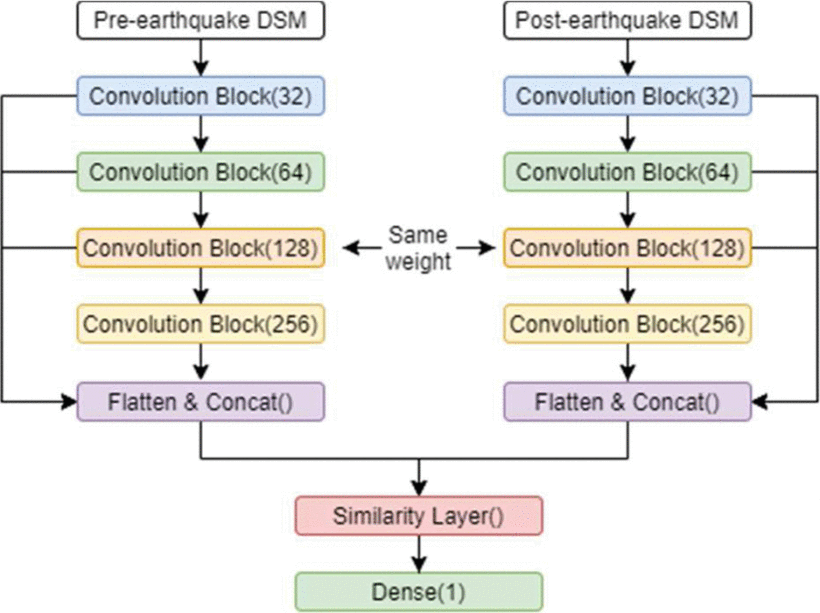 Collapsed Building Detection Using Residual Siamese Neural Network On LiDAR DataMgs M Luthfi Ramadhan, Grafika Jati, Machmud Roby Alhamidi, and 3 more authorsIn 2021 6th International Workshop on Big Data and Information Security (IWBIS), Oct 2021
Collapsed Building Detection Using Residual Siamese Neural Network On LiDAR DataMgs M Luthfi Ramadhan, Grafika Jati, Machmud Roby Alhamidi, and 3 more authorsIn 2021 6th International Workshop on Big Data and Information Security (IWBIS), Oct 2021Evaluation of buildings is crucial to aid emergency response but it costs a lot of resources to do it manually. Many approaches have been proposed to automate the process using artificial intelligence. Most of them, use handcrafted feature, difference calculation between pre-disaster and post-disaster feature, and a classifier model separately. In this study, the process from feature extraction, feature difference and classification are represented by a single model which is siamese neural network. Furthermore, we modify siamese neural network by implementing residual connection for feature concatenation purposes. We evaluate our model on Kumamoto Prefecture earthquake LiDAR data. The result shows the modified model is able to outperform the baseline model with Accuracy and F-measure of 90.91% and 79.28% respectively.
@inproceedings{9631844, author = {Ramadhan, Mgs M Luthfi and Jati, Grafika and Alhamidi, Machmud Roby and P, Riskyana Dewi Intan and Hilman, Muhammad Hafizhuddin and Jatmiko, Wisnu}, booktitle = {2021 6th International Workshop on Big Data and Information Security (IWBIS)}, dimensions = {true}, title = {Collapsed Building Detection Using Residual Siamese Neural Network On LiDAR Data}, year = {2021}, month = oct, volume = {}, number = {}, pages = {29-34}, keywords = {Laser radar;Costs;Neural networks;Buildings;Earthquakes;Information security;Euclidean distance;earthquake;siamese neural network;deep learning;collapsed building assessment}, doi = {10.1109/IWBIS53353.2021.9631844}, }
